An introduction to thinking about risk
I spend what feels like a majority of my waking hours thinking about risk. Professionally, I’ve worked in computer security for fifteen years (and software engineering more generally for longer).So my work days are filled with questions about risk: how risky is this vulnerability? How dangerous is it to launch this new feature if it hasn’t gotten a proper security review yet? How much risk is left after we do that review? And then after work, all my hobbies take place outdoors in the wilderness: backpacking, trail running, packrafting, mountaineering, canyoneering. So my hobbies are also filled with questions about risk: is it safe to cross this river here? What bear safety precautions do I need to take in this area? Is this a safe rapid to run or should I portage?
Professionals who work with risk for living — security engineers, wilderness guides, insurance adjusters, investors, etc. etc. — develop sophisticated tools and mental frameworks to help them think clearly about risk and make good decisions. But people who don’t live in these worlds can often find risk discussions hard to follow. We often use jargon that seem intuitive — words like “risk”, “exposure”, “threat”, “mitigation”, etc. — but has specific and sometimes subtle valances to in-groups.
And without training, it’s easy to fall into traps — risk does weird things to our brain, making us often not think clearly about risky situations. For example, most people feel less safe on an airplane than they do in a car, despite the fact that commercial air travel is many of orders of magnitude safer than car travel. Or: when I tell people about a trip I’m taking to Alaska, most people will ask me the risk of grizzly bears, despite the fact that hypothermia is a much more significant risk. (Bears are just more exciting than shivvering!)
So welcome to a new series about how to think about risk. This series is a crash course, a high-level introduction to the most important concepts and risk frameworks. It’s intended for people who encounter risk from time to time and need some basic tools, but don’t want to make a deep study of it. My hope is that it’ll help you better analyze risk when it comes up for you, and also make it easier to navigate conversations with risk professionals.
You can find all articles in the series here. For this first piece, let’s start at the top: what is “risk”, anyway, and how can we measure it?
Define Risk
Let’s start super-broad with a working definition of Risk. My favorite starting point comes from Deb Ajango, a wilderness medicine and safety educator. In an interview with Alaska Public Media (around the 2:30 mark), she says:
Risk involves the potential for benefit, and the potential for loss. You might have something good happen, but you might have something bad happen.
We wouldn’t bother with risky activities if there wasn’t some benefit. I take long wilderness trips with all sorts of risks (sunburn, Giardia, bears, mosquitos, getting lost, …). I’m not doing these risky things for the risks, but they’re inescapable if I want to achieve the benefit of these trips (visiting beautiful and unspoiled places, satisfying physical accomplishments, learning skills I find fulfilling, …). Likewise, we wouldn’t take risks when building software if they didn’t come with benefits — we wouldn’t decide to launch early without sufficient testing, risking a breach or an outage, if there wasn’t a value to us in getting our work out there. (Eagle-eyed readers will not that word, “sufficient”, which necessarily implies a tradeoff between speed and assurance…)
So: any action we take seeking a benefit will also have some potential for loss. That’s risk.
Decomposing Risk into Likelihood and Impact
However, Risk turns out to be a surprisingly squishy term to work with on its own. For example, consider try to determine which of these scenarios is “riskier”:
A. Your team accidentally deploys a broken build, taking your app down for an hour. B. A foreign government steals your CFO’s credentials, and uses them to steal $1,000,000.
These are both risks, right? But figuring out which is “worse” feels nearly impossible when you’re first starting out. They’re such totally different scenarios that it’s almost impossible to answer that question without some sort of framework for defining risk.
So, nearly every domain that thinks seriously about risk begins with with a definition that decomposes risks into two components:
Risk = Likelihood × Impact
That is, Risk is the product of two factors:
- Likelihood
- How likely is it that some bad thing will happen? So in our example, above – how likely is a bad deploy? How likely is a targeted attack on your CFO?
- Impact1
- If that bad thing does happen, would what be the consequences? So in our example above – what are the costs of an hour-long outage? How badly does a multi-million dollar theft hurt the company?
Some disciplines include a third factor in defining risk. Read more about that third factor: in this sidebar on “Exposure”.
So this gets us closer to comparing these two scenarios. We can now easily see the Scenario A is far more likely, but that Scenario B would have much higher impact.
Measuring Risk
But we’re still not all the way there: we still don’t really have a way of saying which scenario presents the biggest risk.
You can measure risk quantitatively (but you probably don’t want to)
It is possible to measure Likelihood and Impact quantitatively, and thus to express risk in a quantitative way. We could, for example, do something like this:
- We have a 50% chance of a bad deploy causing an outage of an hour or less.
- A outage of an hour costs us $5,000.
- Thus, the Risk Value of this scenario is $2,500/yr (50% × $5,000).
You can probably imaging various ways we might come up with these numbers — analysis of past deploy success rates, business metrics around lost sales, costs of staff time, etc. And you can further imagine doing this for Scenario B, and for other potential risks, and now being able to compare risks directly.
However, in practice this kind of formal analysis is rare, at least in the contexts I’m familiar with (security, engineering, wilderness travel). I’m presenting it first to show that it’s totally possible, that this framework has robust analytical underpinnings, but also to recommend that you don’t try it, at least at first. It seems useful in simple examples where we have few simple scenarios, but imagine trying to do this to analyze all the risk facing an organization. There are an almost infinite number of rabbit holes to go down trying to estimate the probability and outcome of each scenario – it’s terrifically time-consuming. And, mostly importantly, I’ve found I can get 90% of the value of such an exercise out of a far simpler form of analysis that only takes minutes.
I’ve got lots more to say about the pros and cons of quantitative risk measurement – why you might or might not want to use numeric values over more simple risk matrixes – over in this sidebar: Quantitative Risk Revisited
Simple risk measurement
Instead, in most scenarios, it’s sufficient to bucket risk into simple categories based on the likelihood and impact. The absolute simplest version of this is to construct a 2x2 matrix:
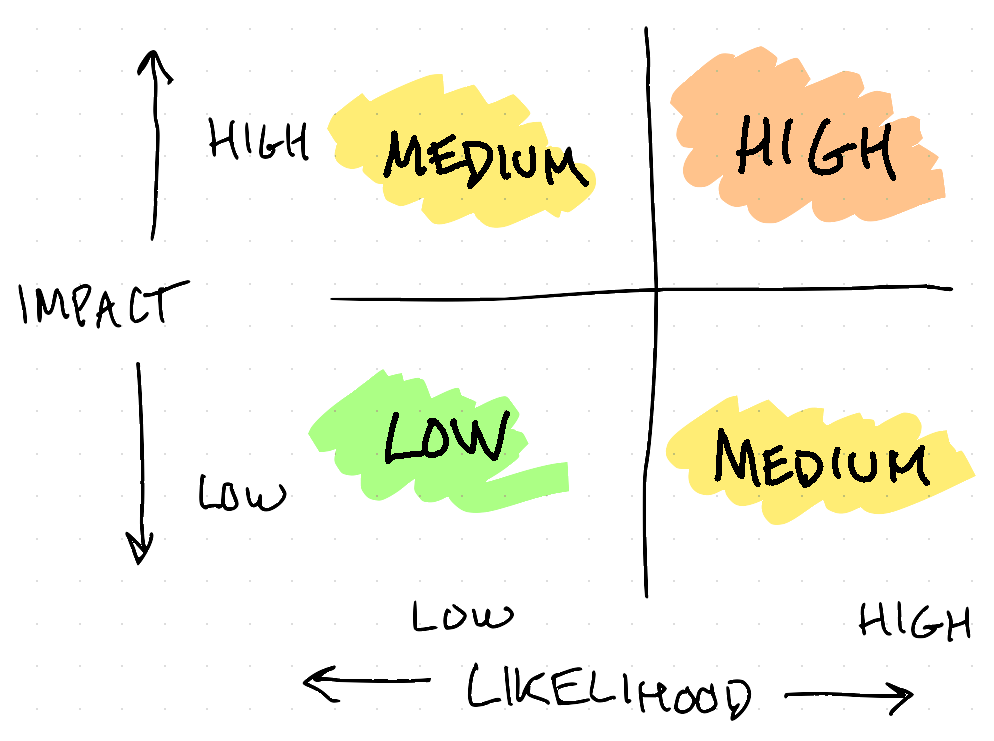
Even something this simple can be surprisingly illuminating. This is the version I use most often in wilderness travel contexts – I’ll lay two trekking poles on the ground to visually construct the matrix – and it’s sufficient to distinguish between, for example, the relative benefits of crossing a river right here versus taking time to scout for better options.
Hey, did you notice that “Medium” is on this chart twice? What’s up with that? More discussion in this sidebar: Two Flavors of Medium Risk
In the information security world, though, it’s most common to see this done as a 3x3 matrix:
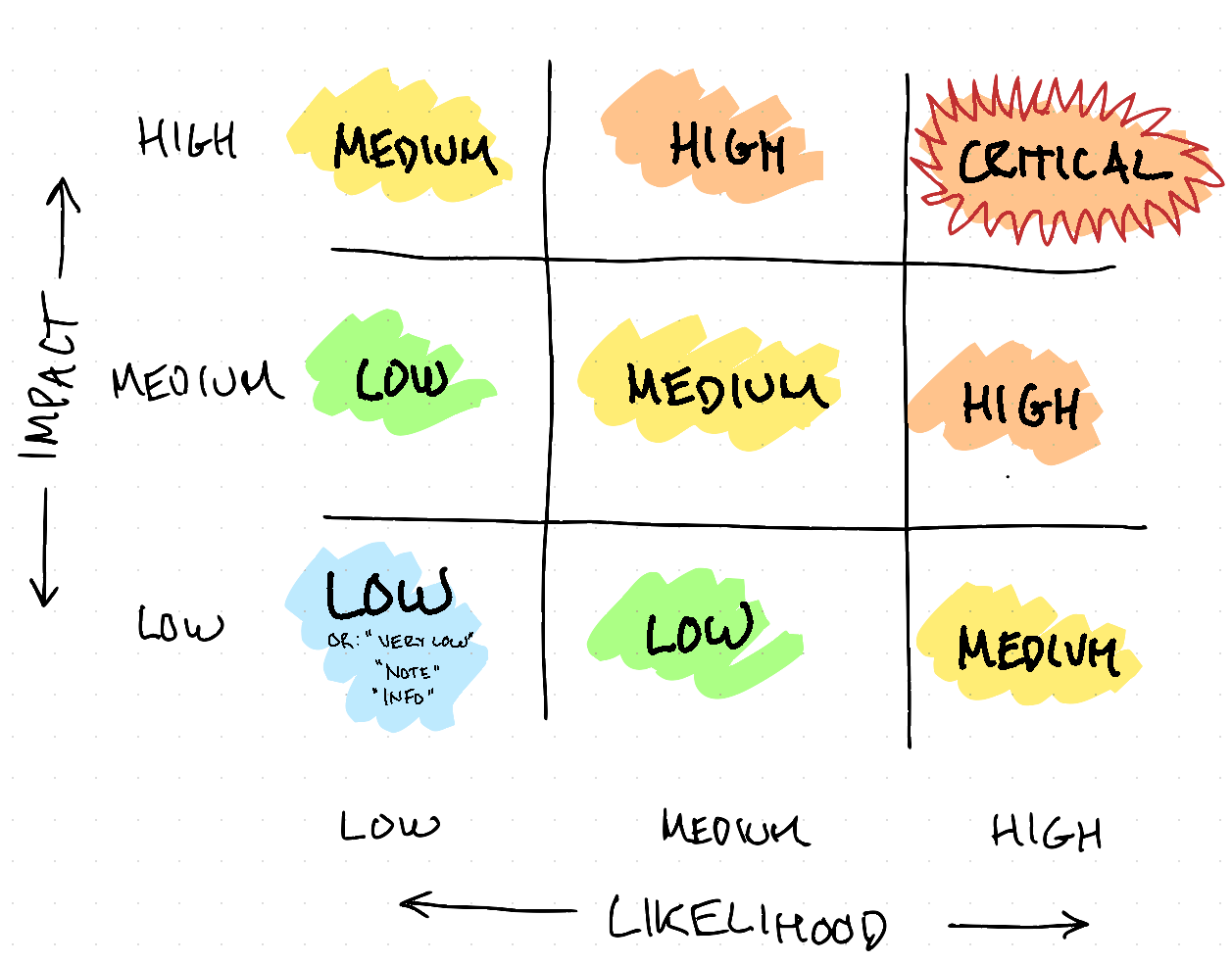
The most widely used version of this 3x3 matrix is probably the OWASP Risk Rating Methodology — many security organizations either use this directly, or create internal metholiodigies using this as a starting point.
Now you have a powerful tool
With this framework in hand, you can use it to start thinking more clearly about risk. Break scenarios down into likelihood and impact, determine rough low/medium/high levels for each, and take the product to get the overall risk. If you want some practice, try applying this framework to the two scenarios presented above. You’ll need to estimate some things — how likely is it that we make a bad deploy? How much of a target is our CFO? — but these are the kinds of questions that are much easier to discuss than the vague “how risky is this?” that we started with.
Next up, we’ll talk about mitigation: once you have a risk, what do you do about it? Stay tuned: you can find all posts in this series here and follow me in various ways. And if you’ve got questions, or topics you’d like to see covered in this series, please get in touch.
People sometimes use a different terms for this factor — “consequences” is common, especially in wilderness risk management circles. I’ve chosen “impact” because it’s most common in the tech industry. ↩︎